Building A Distributed SQL Database in 30 Days with AI

I started with a simple question: can I build a strongly consistent, Redis compatible key/value database using Accord style consensus inspired from Cassandra with AI. To my knowledge the only implementation of Accord is within Cassandra.
The experiment was to iterate fast and keep stacking distributed systems complexity one layer at a time. I also picked Rust for educational chaos since I’ve never written a line of Rust before.
In this post, I’ll break down how I built it step by step. WAL and recovery choices, linearizability verification with Porcupine, dynamic shard splitting, cluster membership and rebalancing flows, and the tooling needed to actually operate it. This is a practical story of ambitious distributed systems design, fast iteration, and rigorous technical steering to keep correctness and performance aligned.
My AI Journey So Far
By 2024-2025, I had AI fatigue like everyone else. Impressive demos, unclear practical value. That changed when I watched engineers I respect using AI to ship real PRs and fix real bugs at scale. I was inspired by David Fowler who is a Distinguished Engineer at Microsoft tweeting about his teams AI journey crunching bugs and tech debt PR’s.
I’ve always been obsessed with database and distributed systems ideas, so I used this project to test both. Build something hard, and learn how to direct AI effectively. If it failed, I’d still learn.
This post is from my third attempt. The first two with Claude Code got surprisingly far, but fell apart around dynamic membership and shard rebalancing where distributed concurrency bugs get brutal fast. For this run, I switched to OpenAI Codex 5.2 Extra High, then 5.3 Extra High and got much further. Claude has improved since then, but I don’t have experience with it yet.
The key detail in this build was that this was not autonomous “AI coding in a void”. The system improved because the human in the loop kept tightening the bar. My motto was high amount of direction, low amount of code review.
HoloStore
First I started with HoloStore which I open sourced last week. My goals with HoloStore was to create a strongly consistent Redis protocol key/value store using Accord style consensus from Cassandra. Over many iterations, we pushed it from it runs to it survives chaos better than it did yesterday.
We implemented the following features:
Stronger crash/restart behavior
Linearizability checks with Porcupine
Dynamic cluster membership and control-plane tooling with holoctl
Dynamic shard split and movement workflows
Recovery hardening around checkpoints and WAL behavior
What is Accord
Accord from the Apache Cassandra world is a consensus transaction protocol built for high concurrency and correctness under conflict, with ideas like:
Conflict-aware ordering
Dependency tracking between transactions
Fast path/slow path commit behavior depending on contention
If two operations do not conflict, Accord can often move quickly. If they do conflict, it falls back to stronger coordination so everyone still agrees.
The point is correct first, then fast when safe.
Start With Correctness Pressure Not Feature Pressure
Early on the real forcing function became:
Can we prove behavior is linearizable?
Can we survive crashes and recover correctly?
Do tests clean up and run consistently?
Since the goal of this experiment was to heavily direct design but lightly review code (I don’t even know Rust LOL) we needed to make every claim measurable. The AI needed correctness tests or else the AI never stood a chance to debug concurrency bugs on its own.
I quickly learned we needed these critical things to move fast with confidence which is not really any different than any other software project but it’s critical with AI.
Design markdown documents. Every new effort I asked the AI to write a design document with phases. This helped me preview how the AI was thinking about the problem and influence its decisions. More design review, less code review.
TODO markdown documents to keep track of things along the way or questions I delayed until later.
End to end integration tests.
Linearizability tests so the AI could measure correctness and automate concurrency bug fixing.
Observability. I’ve learned AI can debug and fix extremely difficult concurrency bugs if you allow it to implement logging, tracing and metrics.
Linearizability testing evolved from one scenario into a suite:
Autosplit
Slow replica
Hot key contention
Client disconnects
Crash during write
Server kill restart
You can read the design of the linearizability tests in this document.
One thing I mentioned to Codex many times was every time it proposed a performance or concurrency bug fix I always asked it to compare to me our fix with how systems I enjoy studying like CockroachDB, etcd and several others. This helped me double check if the AI was doing something that smelled funny and it influenced the AI keeping it focused on the guarantees we were trying to deliver.
Evolution
The first version of HoloStore was completed in the first night. We implemented Accord and the Redis protocol and a couple linearizability tests. Cluster membership was static based on startup arguments and all keys were in-memory only and globally replicated. No partitioning. No durability.
The second version we added on-disk storage durability using Fjall storage engine and primitive WAL (write ahead log) support using raft-engine.
The third version we matured WAL, recovery and added more linearizability correctness tests.
Crash/restart tests
Checkpoint controls
Replay correctness
Checkpoint/manifest corruption handling
The fourth version was the biggest update to date. We added dynamic cluster membership and dynamic shard splitting inspired from CockroachDB. It was a MASSIVE update. This is where all our linearizability tests paid off the most. This took 3 or 4 days to crunch through but unlike previous attempts with Claude, we were not generating a pile of junk code. Tests were starting to pass.

This was extremely exciting! Dynamic sharding grew up. We moved from static partition assumptions toward dynamic range behavior.
Splitting ranges based on load/keys
Preserving correctness during split/cutover
Handling side effects in routing and visibility
At this point we needed better operational tooling. holoctl topology became an operational tool.
Cluster admin tools
Richer topology output
In flight state visibility for shard move/merge workflows.
Where Human Direction Changed the Outcome
I asked Codex for this blog post to summarize how I influenced the design and direction and this is what it came up with.
You repeatedly constrained scope when it drifted.
You asked for “one clear testing strategy,” not fragmented chaos.
You rejected confusing “expected fail” semantics in core suites.
You pushed naming and doc clarity when things were technically correct but operationally confusing.
You insisted on production-oriented behavior over “demo-success.”
In short: AI generated implementation velocity but human direction set engineering quality.
A real pattern we went through many times was “feature complete” moments were more like prototypes.

This is not failure. This is distributed systems development.
People frame AI assisted coding like “you describe an app, machine builds app.”
What actually happened here was
Human sets bar
AI accelerates implementation
Human corrects direction
Tests reveal truth
Both adapt
HoloFusion
After about 3 weeks of cranking on this at night I had a distributed key/value store with dynamic cluster membership, replication and dynamic shard placement that passes a bunch of correctness tests. Next I decided to do something truly bold.
I told Codex to build a distributed SQL engine on top of HoloStore using the Ballista Distributed Query Engine that uses Apache DataFusion and we added Postgres protocol support using DataFusion-Postgres.
A HoloFusion node embeds a Postgres protocol server, Ballista DataFusion execution node and a HoloStore Accord consensus node and the process layout looks like this.
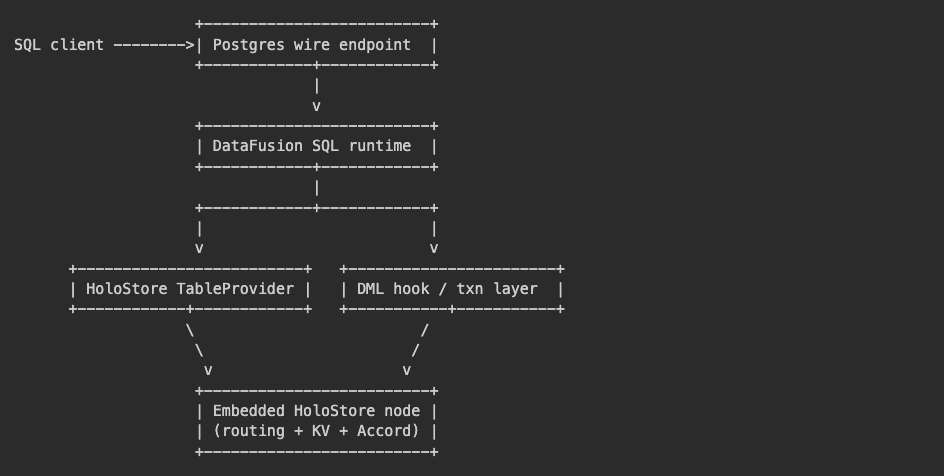
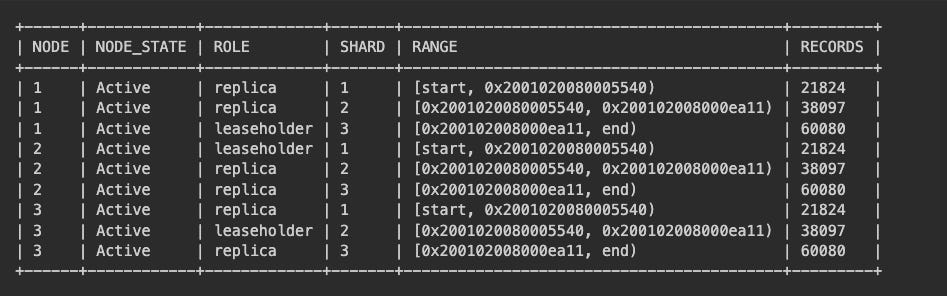
It’s SO exciting to execute SQL against this 30 day old distributed database. Check this out!
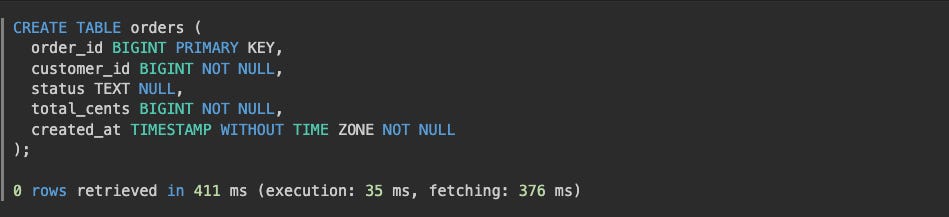
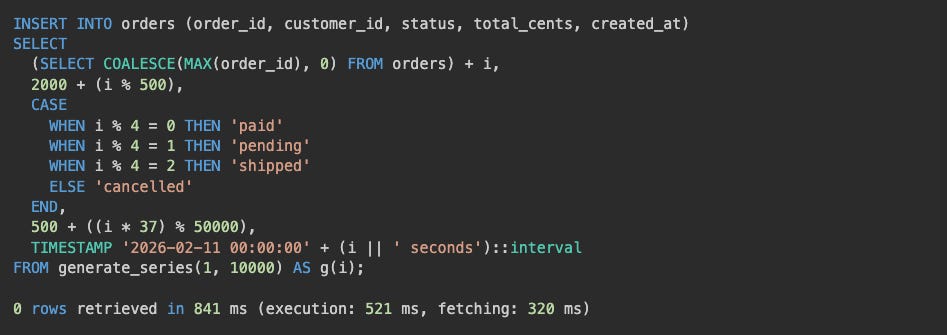
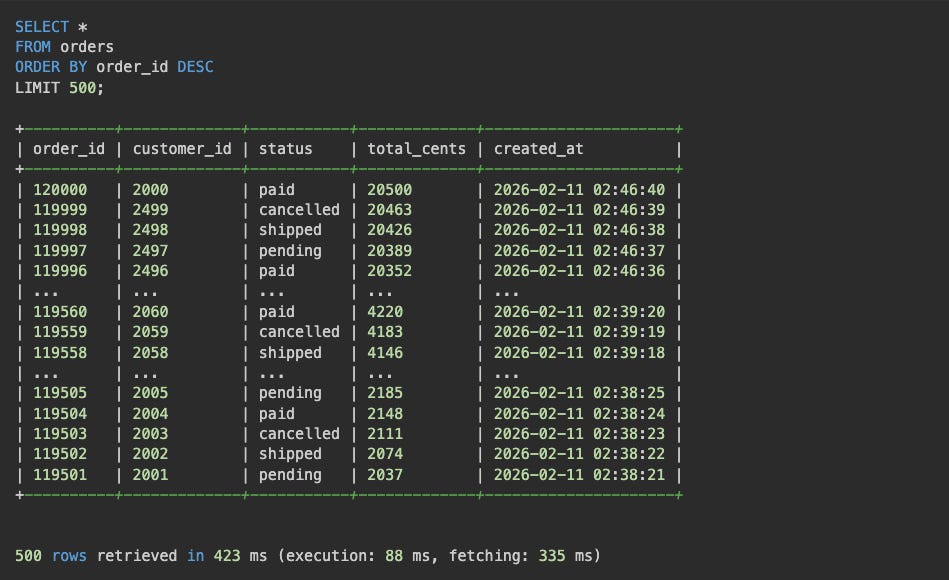
After inserting many more rows we can see the cluster splitting row shards and shuffling them around the cluster!
Final Words
What’s next for HoloStore and HoloFusion? Who knows! Feel free to suggest some direction.
I’m enjoying this journey and I’m not confusing this with a mature system and I’m well aware that there’s minimal SQL support and probably a bunch of bugs or feature gaps. As I’ve always done on Twitter and social media, I enjoy learning in public and sharing early.
I am impressed it passes correctness tests under dynamic shard relocation and performance doesn’t seem terrible either. I don’t know Rust, but the code doesn’t look like a shit show to me but I would love some Rust experts to give me an idea what they think of the code base so far.
Can AI build complex distributed systems and troubleshoot its own concurrency bugs? Yes I think it can, with the right preparation.
Please be kind with your feedback this is very raw and understand this is an early experiment but I’m so excited to hear your thoughts.
Links
HoloStore
HoloStore Design Documents
HoloFusion Design Documents